AI Data Extraction and Document Recognition
Let generative AI recognize and digitize all incoming documents and extract all relevant information to manage cases
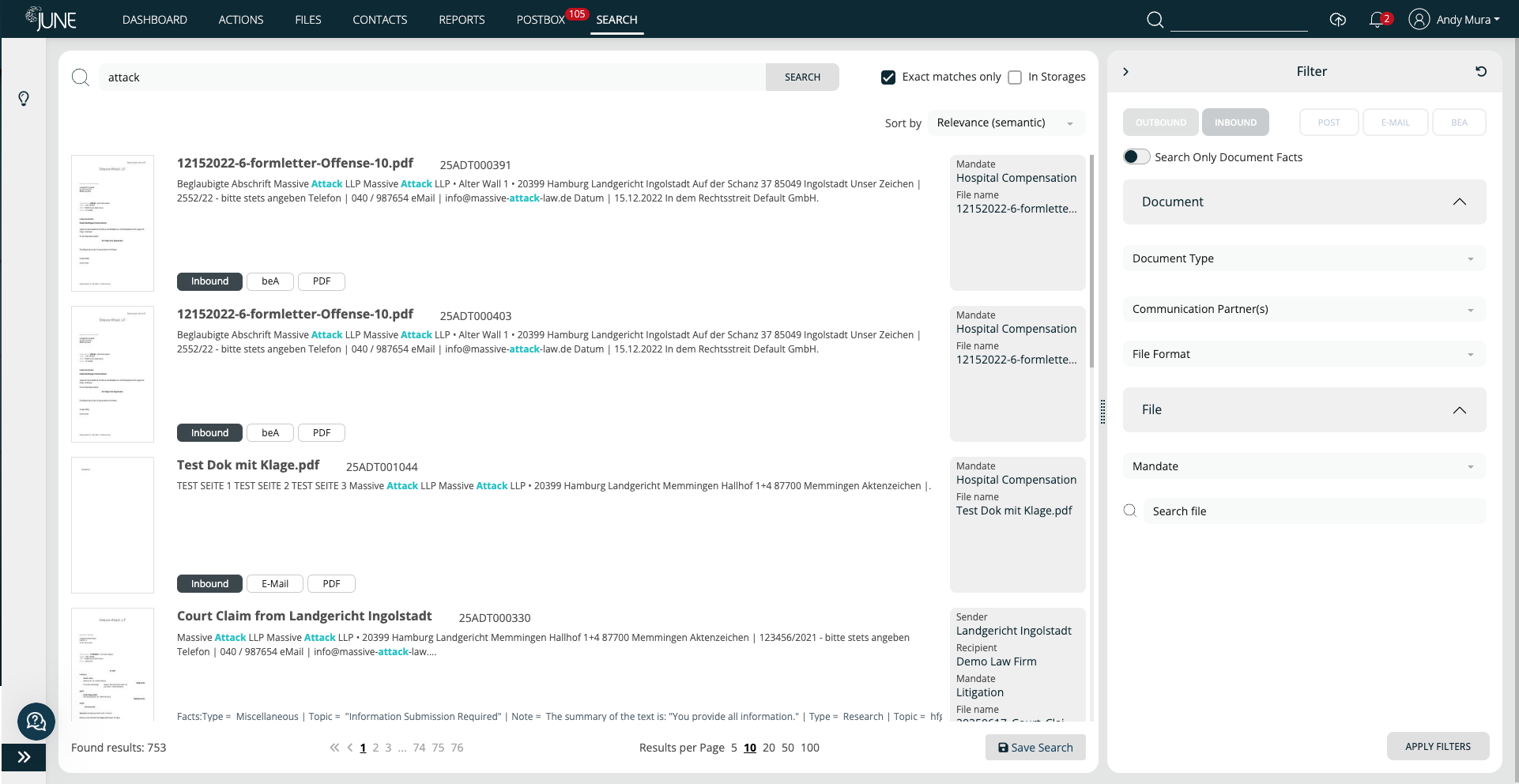
Next Gen Document Analysis
Automated
Avoid manual process in documents
Intelligent
Turn unstructured data into structured information
Precise
Rely on a self-learning system that keeps getting smarter
Accelerate legal work through intelligent data extraction and document classification
Efficient right out of the box
On top of classic Natural Language Processing (NLP), intelligent Optical Character Recognition (OCR), Machine Learning (ML), and Computer vision, JUNE data extraction and classification processes are carried out by leveraging the latest generative AI resources to allow you to immediately convert documents into structured insights from the get-go without a long pre-training phase and tons of training data.
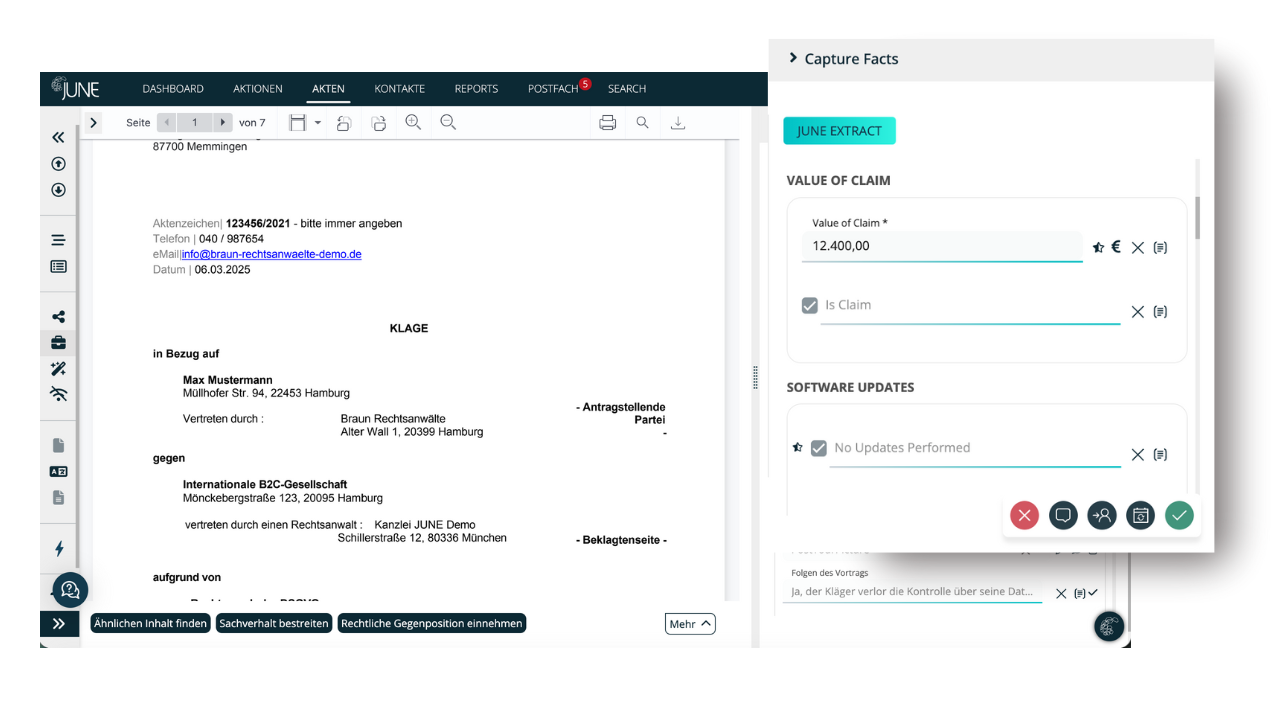
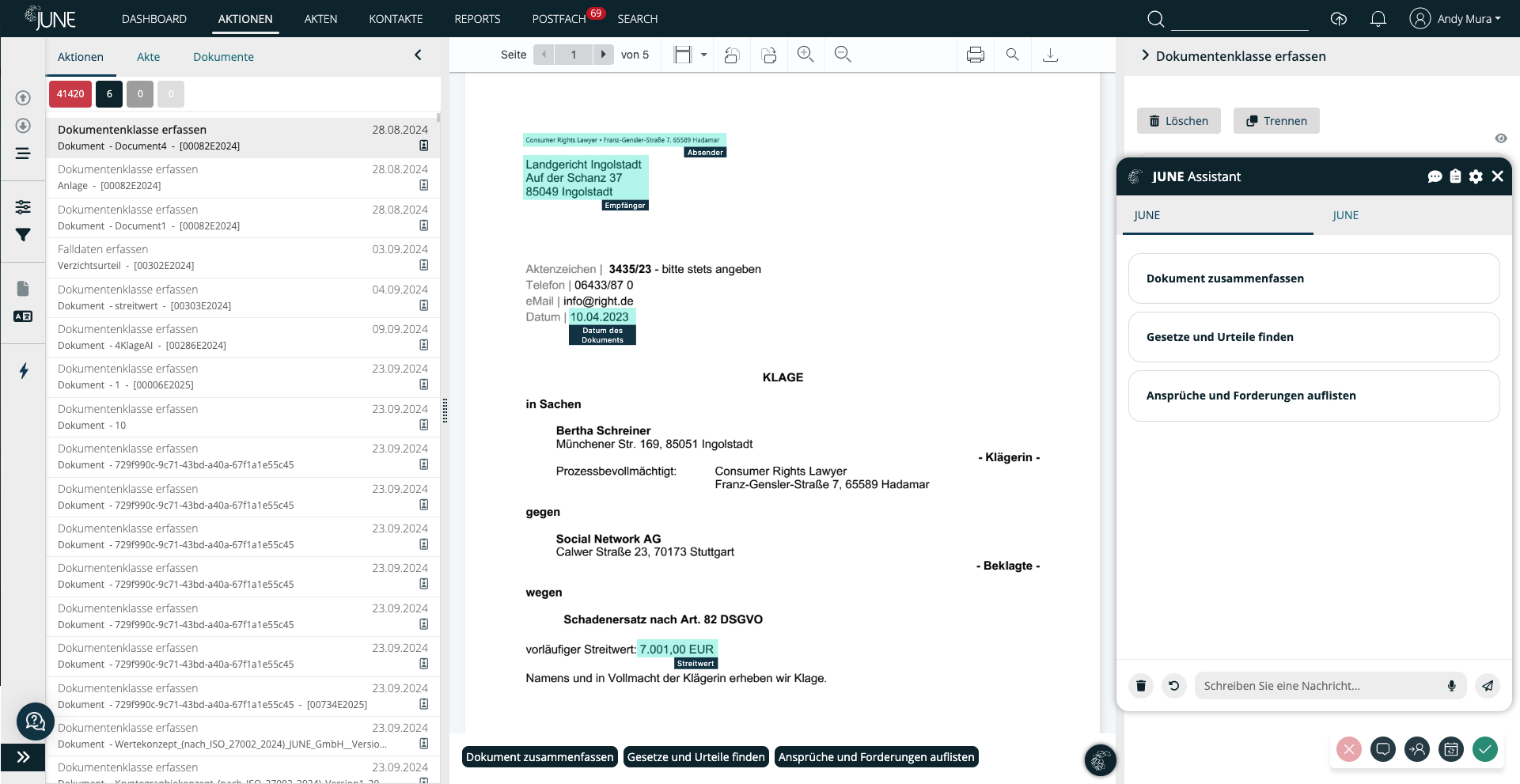
Full control: Extract exactly the information you need
With JUNE, you define your own fact structures for every document type, ensuring the platform extracts precisely the information required for your specific use case. Whether you’re searching for automotive data, airline information, economic indicators, contractual clauses, or complete legal arguments, JUNE captures it all with contextual accuracy. The system can surface the positions raised by opposing parties, identify which paragraphs form the legal assessment, analyze contract clauses, or even determine whether an NDA is legally valid in its current form. From simple metadata to highly complex legal reasoning, JUNE transforms unstructured documents into structured knowledge you can act on instantly.
Test, optimize, and automate extraction at enterprise scale
Before going live, you can refine your extraction logic in a dedicated testing environment, perfecting prompts, adding examples, and defining the exact data formats you want returned. Even sophisticated structures such as lists and tables can be generated cleanly by the AI.
Once activated, your extraction setup is fully integrated into JUNE’s intake pipeline: every incoming document is automatically classified and enriched with your data fields in real time. This seamless automation eliminates up to 80% of previously manual data entry work, dramatically accelerating case processing while improving accuracy across your entire legal workflow.
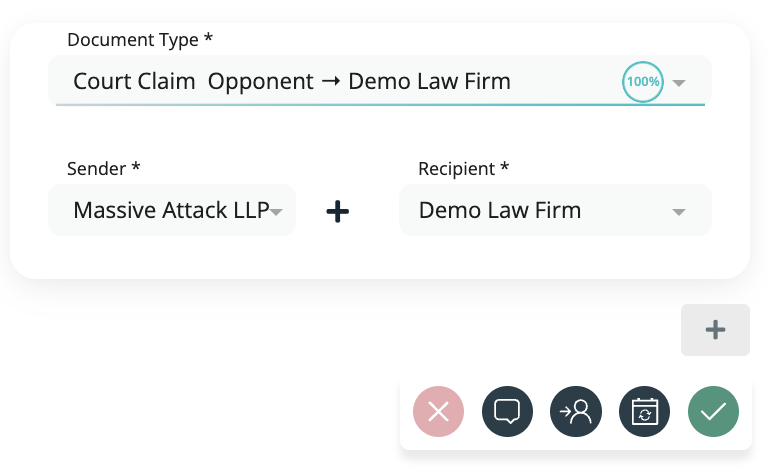
Smarter with each document
Thanks to the evolutionary nature of generative AI, extraction and classification capabilities are constantly evolving, and this affects document classification. JUNE is a self-learning system that becomes smarter with every new document it processes. The more you work with JUNE, the smarter the system gets, without the need for manual training.
No document left behind
JUNE automatically classifies any sort of incoming document and turns it into structured data and insights independently of the kind of document and source. Cases often involve several forms of records, from emails to PDFs, handwritten documents, or forms, and JUNE deals with each format efficiently while allowing you to gather all information into a single platform for case management.
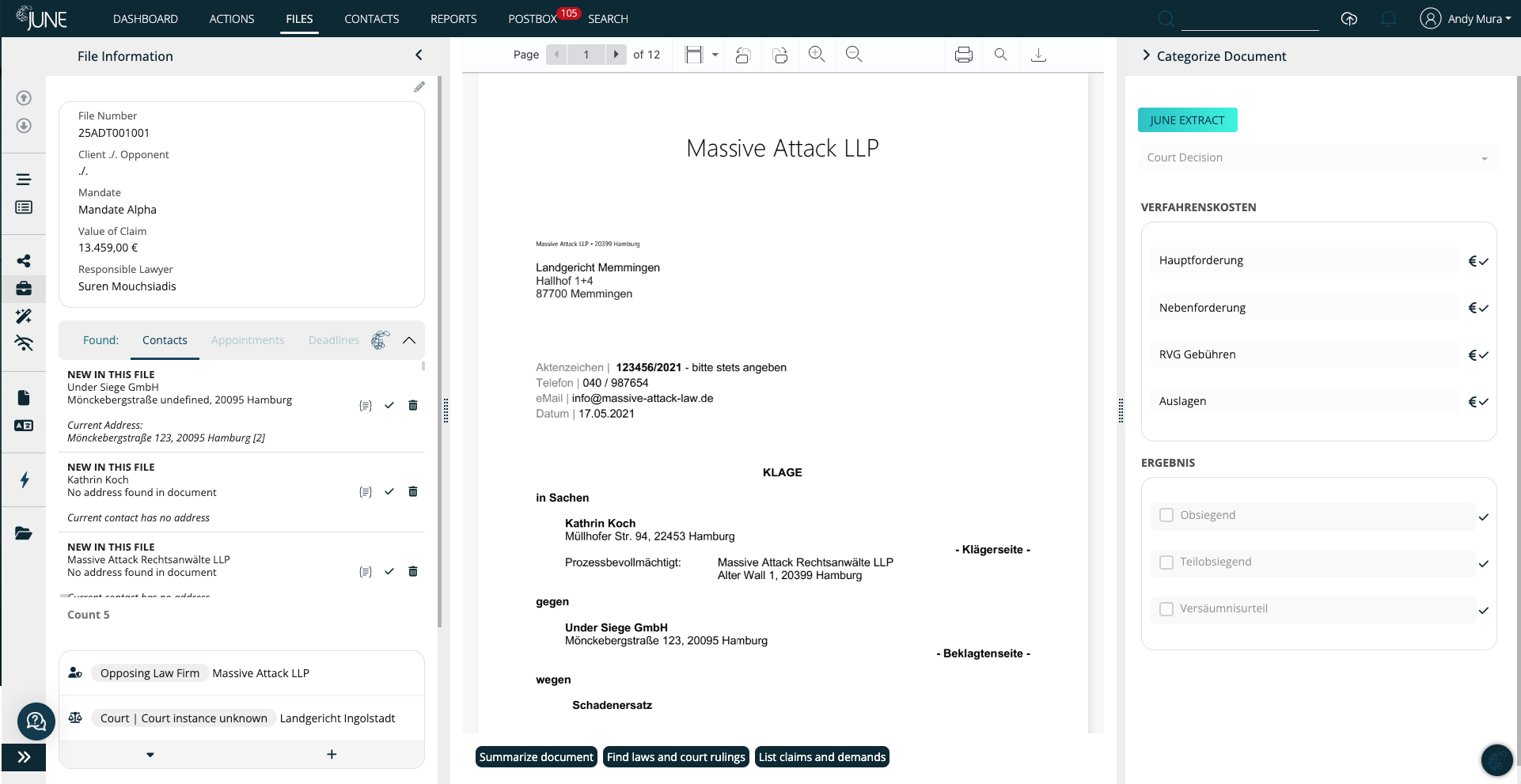
Keeping track of references
Extracted data is always connected to the source document. With a single click, you can always go back from any piece of information to the original source from which facts and dates were extracted. This way, you can always immediately find corresponding records and the precise location within the document in which the information was contained.
From data extraction to action
Through the multi-step process of document classification and data extraction, the system “understands” incoming documents, their structure and purpose, and is able to isolate all the information and insights required to process the case. This data is then fed directly into the system to automate legal processes with customizable workflows. Even though data extraction and document classification are core elements in the platform, JUNE doesn’t just take care of document analysis but uses this as a starting point to optimize and speed up legal workflows as a whole.